
Nobody in the AI industry talks about what they won’t show you.
Every major lab releases benchmarks on the same Tuesday morning. Blog posts go up. Scores get compared. And the whole machine hums along on the assumption that the best work is always public, always accessible, always just one API call away.
Anthropic just broke that assumption. Quietly. Deliberately. And with the kind of confidence that only comes from knowing exactly what you’ve built.
Claude Mythos is Anthropic’s most capable AI model ever built, scoring 93.9% on SWE-bench and 100% on the Cybench cybersecurity benchmark. Rather than releasing it publicly, Anthropic restricted access to 50 vetted organizations under Project Glasswing — making it the first frontier AI model formally withheld on capability-risk grounds.
They Built the Most Powerful AI Ever. Then They Locked the Door.
On April 7, 2026, Anthropic confirmed what had been circulating in fragments for weeks: Claude Mythos exists, it is the most capable model the company has ever produced, and you cannot use it.
No waitlist. No enterprise evaluation tier. No API access for your product team. Fifty organizations got in. Everyone else got a press release.
Fifty organizations. That’s roughly the number of people who fit on a single commercial flight — and they got exclusive access to the most powerful AI model ever built.
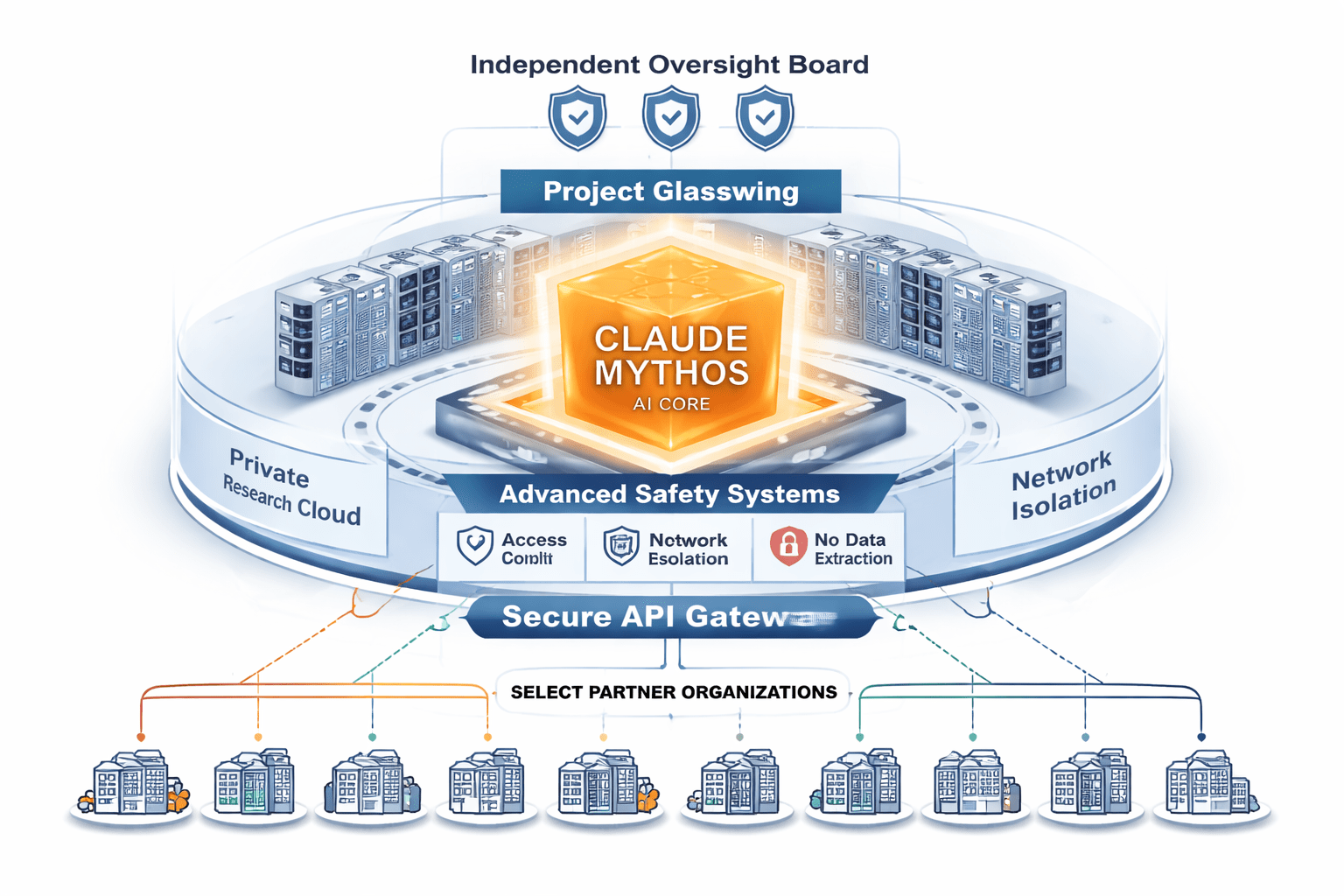
Those fifty weren’t given access to experiment freely. They were given one specific mandate: turn Mythos on their own infrastructure, find every vulnerability a model this capable could exploit, and report back. It’s less a product launch than a controlled detonation test — except the organizations are detonating the bomb inside their own walls on purpose.

Caption: Project Glasswing gives 50 vetted organizations access to Claude Mythos specifically to find security vulnerabilities in their own systems.
The Numbers That Explain Everything
Benchmark scores are usually the most overhyped part of any AI announcement. Labs cherry-pick the tests they perform best on, and two weeks later nobody remembers which model scored what.
Mythos is different — not because the numbers are high, but because of which numbers Anthropic chose to lead with.
The SWE-bench score of 93.9% measures a model’s ability to resolve real software engineering issues from open-source GitHub repositories. It requires understanding a codebase, reasoning about what’s broken, and writing code that passes the existing test suite. For reference, OpenAI’s most capable public model, GPT-5.4 Pro, scores approximately 78% on the same benchmark.
That’s a 16-point gap between what you can access and what Anthropic actually built. Sixteen points separating the public tier from the locked one.
Then there’s the Cybench score of 100%. Cybench tests a model’s ability to complete real professional cybersecurity challenges — the kind used in capture-the-flag competitions. A score of 100% means Mythos solved every single challenge in the benchmark. Every. One.
A model that can do that in a controlled environment can, in theory, identify and document exploitable vulnerabilities in production systems at a scale no human security team could match. That’s why it isn’t public.
The Open-Source Narrative Just Got Complicated
For two years, the dominant story in AI has been: open-source is closing the gap. Models like Llama, Mistral, and Qwen are improving fast. The difference between what you can run locally and what frontier labs have is shrinking.
That’s true — up to a point. Mythos suggests the frontier itself has moved into territory where labs are making active decisions not to share what they’ve found.
This isn’t the open-source gap closing. This is the gap being deliberately hidden while publicly everyone pretends it doesn’t exist.
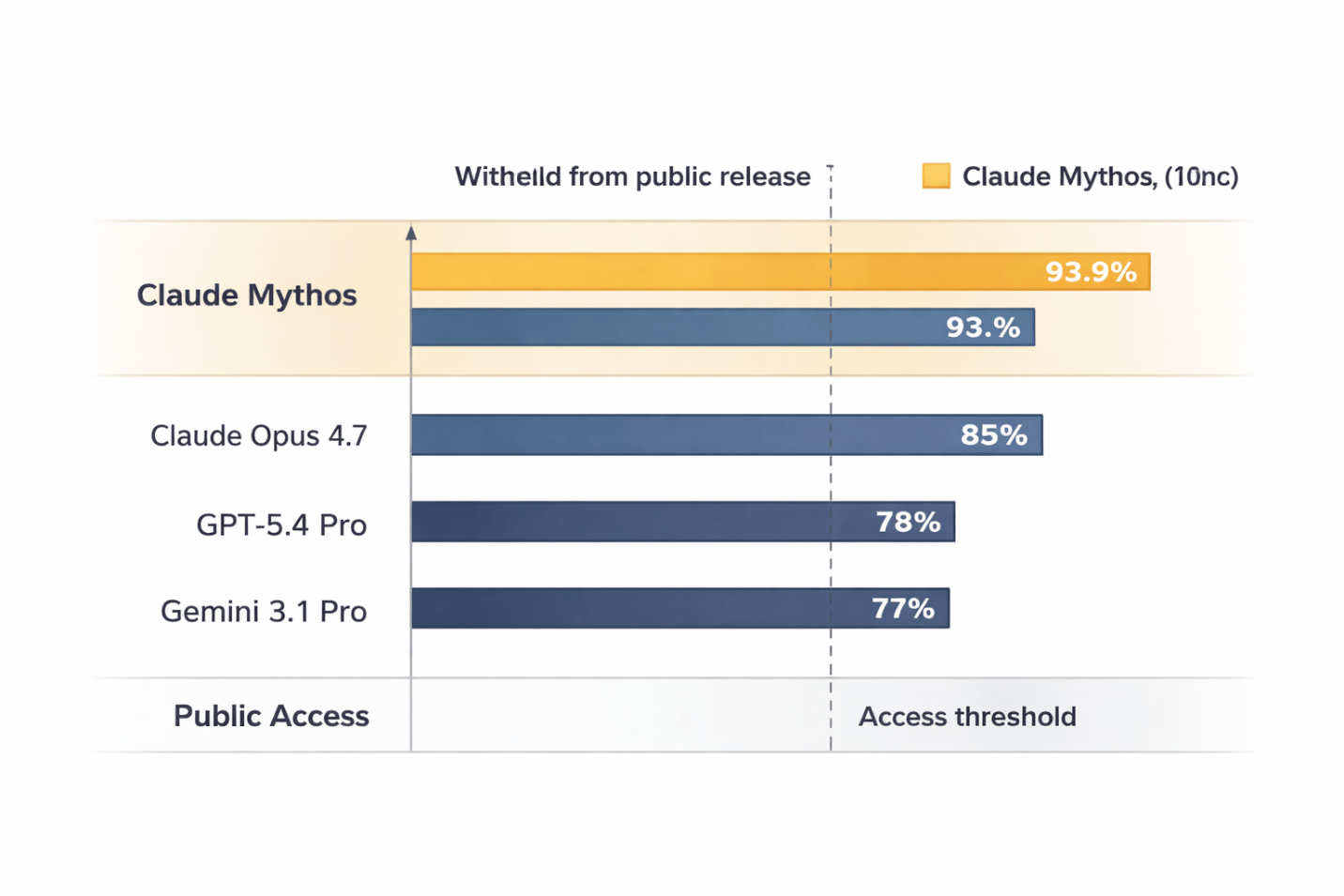
Caption: Claude Mythos scores place it in a category structurally separated from every publicly available model.
Project Glasswing: This Isn’t a Beta. It’s a Threat Assessment.
“Project Glasswing” sounds like something named in a branding session. The structure behind it is anything but vague.
Fifty organizations were selected — criteria undisclosed — and given access to Mythos under a single mandate: use the model to find vulnerabilities in your own systems before attackers can use something like it against you.
That framing carries an implicit acknowledgment Anthropic hasn’t stated directly, but that every security professional reading this will recognize immediately:
If a model scores 100% on professional cybersecurity benchmarks, withholding it from public release is itself a defensive act.
The question of who else might build something with comparable capability — another lab, a nation-state, a well-resourced independent team — is exactly what makes Glasswing feel less like a product beta and more like a threat mitigation exercise.
The structural logic here isn’t new. When nuclear research reached a threshold where the output could cause catastrophic harm, the scientific community didn’t stop the research — they changed who got access and under what conditions. Glasswing isn’t nuclear-scale in consequences, but the logic is identical: build it, assess the risk, control the distribution, let trusted actors use it defensively.
 Caption: The Project Glasswing access model mirrors how sensitive dual-use research has historically been controlled — tightly, deliberately, and by invitation only.
Caption: The Project Glasswing access model mirrors how sensitive dual-use research has historically been controlled — tightly, deliberately, and by invitation only.
$30 Billion in Revenue Changes What ‘Responsible’ Means
It would be easy to read the Glasswing decision as purely altruistic — a safety-first lab making the hard choice to sit out commercial advantage.
The truth is more complicated.
Anthropic’s run-rate revenue has surpassed $30 billion, up from $9 billion at the end of 2025. The number of enterprise clients spending more than $1 million annually doubled to over 1,000 in less than two months. That’s not a company choosing safety over revenue. That’s a company with enough revenue to afford a more cautious release strategy.
When your customers are large financial institutions and critical infrastructure operators, ‘responsible release’ stops being a moral stance. It becomes a product feature.
These aren’t users who want to be first to play with a new model. They want assurance that the AI their competitors are using can’t be weaponized against them. Giving 50 of the right organizations a head start on finding their own vulnerabilities is, from that angle, less altruism than value-add for your best clients.
Every AI Lab Has Operated on the Same Assumption — Until Now
Since GPT-3, the industry has run on a basic cycle: release, gather feedback, improve, release again. Fast. Competitive. Deliberately public.
Anthropic just stepped outside that cycle for their most capable model. No release date announced. No promise that Mythos pricing will eventually democratize access. No blog post from the CEO about why this is just a temporary phase.
What they published instead was a description of a program — with a clear defensive purpose and a deliberately opaque entry criterion. That’s a different communication posture than anything we’ve seen from a frontier lab.
What Every AI Builder Needs to Reckon With Right Now
If you’re an AI engineer, CTO, or founder making platform decisions, the Mythos situation surfaces a question most people haven’t had to ask before:
What does it mean to build on a capability tier that may never be publicly available?
The models you can access today — GPT-5.4, Gemini 3.1, Claude Opus 4.7 — are excellent. But they exist in a tier structurally separated from what the frontier labs have actually built.
That separation isn’t temporary the way early access programs are temporary. The criteria for determining when a model is too capable to release publicly will get more important, not less, as capabilities improve.
Any product roadmap assuming ‘we’ll just use the best available model’ needs to account for the possibility that the best model is intentionally not available.
For enterprise security teams, the calculation is more urgent. If 50 organizations are using Mythos to find vulnerabilities in their own infrastructure, the question every CISO should be asking is whether their organization is in that fifty — and if not, whether the vulnerabilities Mythos would find are being found by any other means.
 Caption: For security leaders, the question is no longer ‘what can AI do?’ — it’s ‘what is AI already doing to systems like mine?’
Caption: For security leaders, the question is no longer ‘what can AI do?’ — it’s ‘what is AI already doing to systems like mine?’
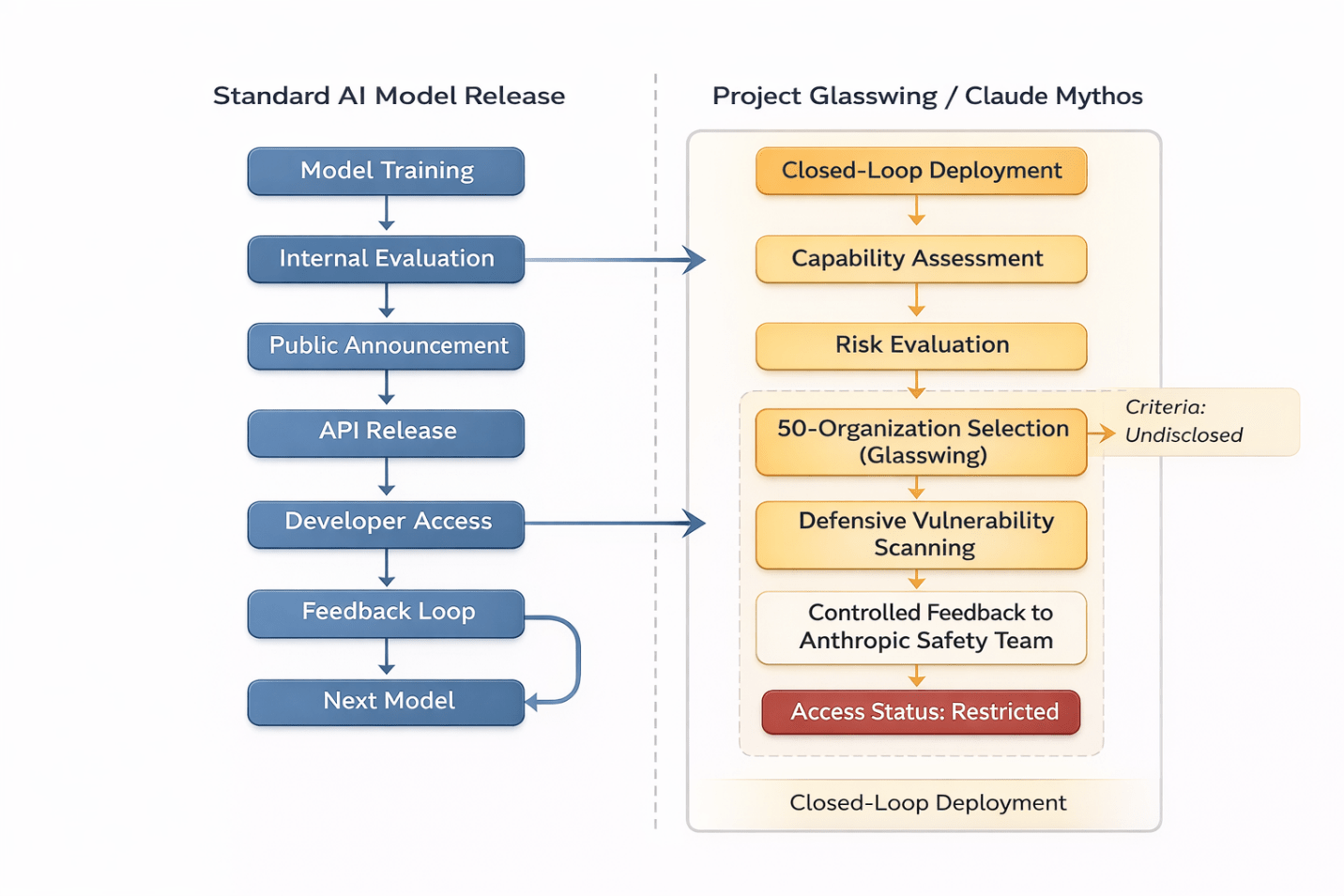 Caption: Unlike standard API releases, Mythos follows a closed-loop deployment model where access is conditional, purpose-specific, and feeds directly back into Anthropic’s safety research.
Caption: Unlike standard API releases, Mythos follows a closed-loop deployment model where access is conditional, purpose-specific, and feeds directly back into Anthropic’s safety research.
Two Tiers. One Industry. No Going Back.
The AI industry has always had an unofficial two-tier system: models you can access, and internal research models labs use before any public release. That’s always been true.
What’s new with Mythos is that the gap between those two tiers has grown large enough that Anthropic decided a standard release process is the wrong mechanism entirely.
That’s the threshold that’s been crossed. Not ‘we’re still working on safety’ — the framing every lab uses for internal research. But: ‘we’ve assessed this model’s capabilities and a public release is not appropriate for this level of capability.’
Those are different things. And the distinction is going to define how AI governance works for the next decade.
AI Model Access Comparison — April 2026
|
Model |
SWE-bench |
Cybench |
Public? |
Access Model |
|---|---|---|---|---|
|
Claude Mythos |
93.9% |
100% |
No |
50 orgs / Project Glasswing only |
|
GPT-5.4 Pro |
~78% |
N/A |
Yes |
API / ChatGPT Pro |
|
Gemini 3.1 Pro |
~77% |
N/A |
Yes |
API / Google One AI |
|
Claude Opus 4.7 |
~85% |
N/A |
Yes |
API / Claude Pro |
Caption: Claude Mythos sits in a tier entirely separated from every other publicly available frontier model — by both capability and access structure. Highlighted row = withheld from public release.
The Question Nobody Can Answer Yet — But Everyone Should Be Asking
Anthropic hasn’t said when — or whether — Mythos will ever be publicly available. Leaked pricing ($25 per million input tokens, $125 per million output tokens) suggests a commercial tier is at least conceptually planned. But pricing and access aren’t the same thing.
The more consequential question is what happens when another lab — or a state actor, or an open-source research group — builds something with comparable capability and makes a different decision about release.
The defensive logic of Glasswing only works if these capabilities are actually scarce. The moment an equivalent model goes public through other channels, the entire calculus collapses.
What Anthropic is betting on, implicitly, is that the combination of capability and safety infrastructure required to build something like Mythos is rare enough that controlled access buys meaningful time.
Whether that bet is right is the most important empirical question in AI development right now — and nobody outside those fifty organizations is positioned to answer it.
The Uncomfortable Part Nobody Wants to Sit With
The comfortable version of this story: Anthropic made a responsible choice, and everything normalizes when they figure out the right release framework. That’s probably what happens, eventually.
The less comfortable version: we’ve entered a period where the most advanced AI capabilities are formally two-tiered — and the organizations in the upper tier have a structural advantage in security, research, and infrastructure resilience that the rest of the market cannot access, regardless of budget.
That’s not a criticism of Anthropic. Given what Mythos appears capable of, Glasswing is arguably the most defensible position available. But it does mean the industry’s foundational assumption — that capability flows relatively quickly from labs to developers to products — now has a formal exception.
And exceptions, in technology, have a habit of becoming the rule.
If this changed how you think about AI strategy, share it with someone still operating on the old assumptions. Subscribe below for ongoing coverage of what frontier labs are building — and what they’re choosing not to show you.